
Research
Causality
My research in causality is driven by a profound curiosity to unravel the hidden mechanisms that govern complex systems. This is characterized by two intertwined paths: causal discovery/inference in the presence of latent variables [1-4] and designing experiments [5-8] to facilitate learning through interventions. These endeavors are not just academic exercises but are crucial bridges that connect theoretical understanding with real-world applications, thereby contributing to various scientific fields and societal advancements.
I am currently focusing on designing an end-to-end solution for the task of causal inference. This process begins by learning a causal model from available data, incorporating both observational and interventional inputs. Then, from the current knowledge about the underlying causal model, we try to get an estimate of the causal effect in the identification analysis stage. If an accurate estimation is not feasible, we design a limited number of interventions to be performed in the environment to refine our knowledge about the underlying causal system. By closing this loop, we aim to establish a comprehensive framework for causal inference tasks.
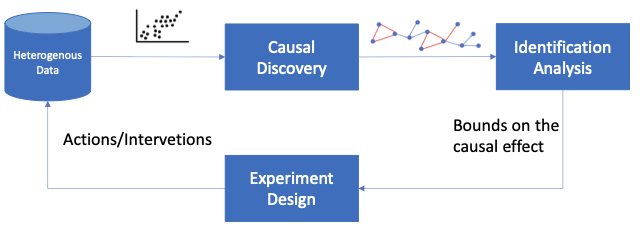
An End-to-End Causal Inference Framework
Stochastic Optimization
In the past few years, I have been working on developing efficient optimization algorithms for training large learning models with applications in federated learning [9-12] and reinforcement learning [13-14]. Currently, I am mainly focused on the following directions:
- Developing algorithms for hyper-parameter optimization: Very recently, we proposed MetaOptimize framework [15] which dynamically adjusts meta-parameters, particularly step sizes, during training. More specifically, MetaOptimize can wrap around any first-order optimization algorithm, tuning step sizes on the fly to minimize a specific form of regret that accounts for the long-term effect of step sizes on training, through a discounted sum of future losses.
- Direct preference optimization in generative AI: I am working on designing optimization algorithms for directly aligning generative models from human preference data, eliminating the need for an explicit reward model in common multi-stage training methods.
References
[1] Salehkaleybar, S., Ghassami, A., Kiyavash, N. and Zhang, K., 2020. Learning linear non-Gaussian causal models in the presence of latent variables. The Journal of Machine Learning Research, 21(1), pp.1436-1459.
[2] Ghassami, A., Salehkaleybar, S., Kiyavash, N. and Zhang, K., 2017. Learning causal structures using regression invariance. Advances in Neural Information Processing Systems, 30.
[3] Kivva, Y., Salehkaleybar, S. and Kiyavash, N., 2023. A Cross-Moment Approach for Causal Effect Estimation. Advances in Neural Information Processing Systems.
[4] Salehkaleybar, S., Etesami, J., Kiyavash, N. and Zhang, K., 2018, April. Learning vector autoregressive models with latent processes. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1).
[5] Ghassami, A., Salehkaleybar, S., Kiyavash, N. and Bareinboim, E., 2018, July. Budgeted experiment design for causal structure learning. In International Conference on Machine Learning (pp. 1724-1733). PMLR.
[6] Ghassami, A., Salehkaleybar, S., Kiyavash, N. and Zhang, K., 2019, July. Counting and sampling from Markov equivalent DAGs using clique trees. In Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01, pp. 3664-3671).
[7] AhmadiTeshnizi, A., Salehkaleybar, S. and Kiyavash, N., 2020, November. Lazyiter: a fast algorithm for counting Markov equivalent DAGs and designing experiments. In International Conference on Machine Learning (pp. 125-133). PMLR.
[8] Mokhtarian, E., Salehkaleybar, S., Ghassami, A. and Kiyavash, N., 2023. A unified experiment design approach for cyclic and acyclic causal models. Journal of Machine Learning Research, 24(354), pp.1-31.
[9] Salehkaleybar, S., Sharifnassab, A. and Golestani, S.J., 2021. One-shot federated learning: theoretical limits and algorithms to achieve them. The Journal of Machine Learning Research, 22(1), pp.8485-8531.
[10] Sharifnassab, A., Salehkaleybar, S. and Golestani, S.J., 2019. Order optimal one-shot distributed learning. Advances in Neural Information Processing Systems, 32.
[11] Sharifnassab, A., Salehkaleybar, S. and Golestani, S.J., 2023. Order Optimal Bounds for One-Shot Federated Learning over non-Convex Loss Functions. IEEE Transactions on Information Theory.
[12] Sharifnassab, A., Salehkaleybar, S. and Golestani, S.J., 2019, September. Bounds on over-parameterization for guaranteed existence of descent paths in shallow ReLU networks. In International conference on learning representations.
[13] Masiha, S., Salehkaleybar, S., He, N., Kiyavash, N. and Thiran, P., 2022. Stochastic second-order methods improve best-known sample complexity of sgd for gradient-dominated functions. Advances in
Neural Information Processing Systems, 35, pp.10862-10875.
[14] Salehkaleybar, S., Khorasani, M., Kiyavash, N., He, N. and Thiran, P., 2022. Momentum-Based Policy Gradient with Second-Order Information.
[15] Sharifnassab, A., Salehkaleybar, S. and Sutton, R., 2024. MetaOptimize: A Framework for Optimizing Step Sizes and Other Meta-parameters. arXiv preprint arXiv:2402.02342.